
If you’re interested in SEO, you’ve probably wondered about how search engines work. Especially, Google's search engine, since approximately 87% of all online searches are done in Google. Having the lion’s share of the search engine market, Google is without a doubt the main search engine that SEOs care about – although this might not be the case depending on your location.
However, all search engines have the same goal: to locate information online that best matched the terms that were searched. But is that all it is? How do search engines work anyway? In this article, we’ll answer that question thoroughly. Let’s start with the basics.
Table of Contents
1. The primary actions of a search engine
There are three primary actions that a search engine goes through which describe how search engines work. We’ll discuss them quickly:
Crawl
Crawlers (or bots – we’ll explain this concept further along this article) travel the internet looking for new content to add to their index. They read all the content and code on each URL.
Index
The search engine stores all the information collected during the crawling process, and prepares them to be matched to specific searches.
Rank
Ranking connects the content indexed to the results that best match the user query, attributing a position in the search results for each URL in order to best serve users with the content they’re after. They are sorted from the most relevant to the least relevant in the search results.
2. Crawling
This is the first step in the search process. In order for your website to be crawled, you need to make sure that every single piece of content and code are crawler-friendly. There are two main things you need to do in order for your website to be accurately crawled: using a robots.txt file and defining URL parameters on Google Search Console. ⚙️
2.1. Can search engines find every page on your website?
In order for your website to rank for specific keywords you have chosen, it needs to be crawled and indexed. The first thing you need to do is to use the “site:yourdomain.com” search on Google.
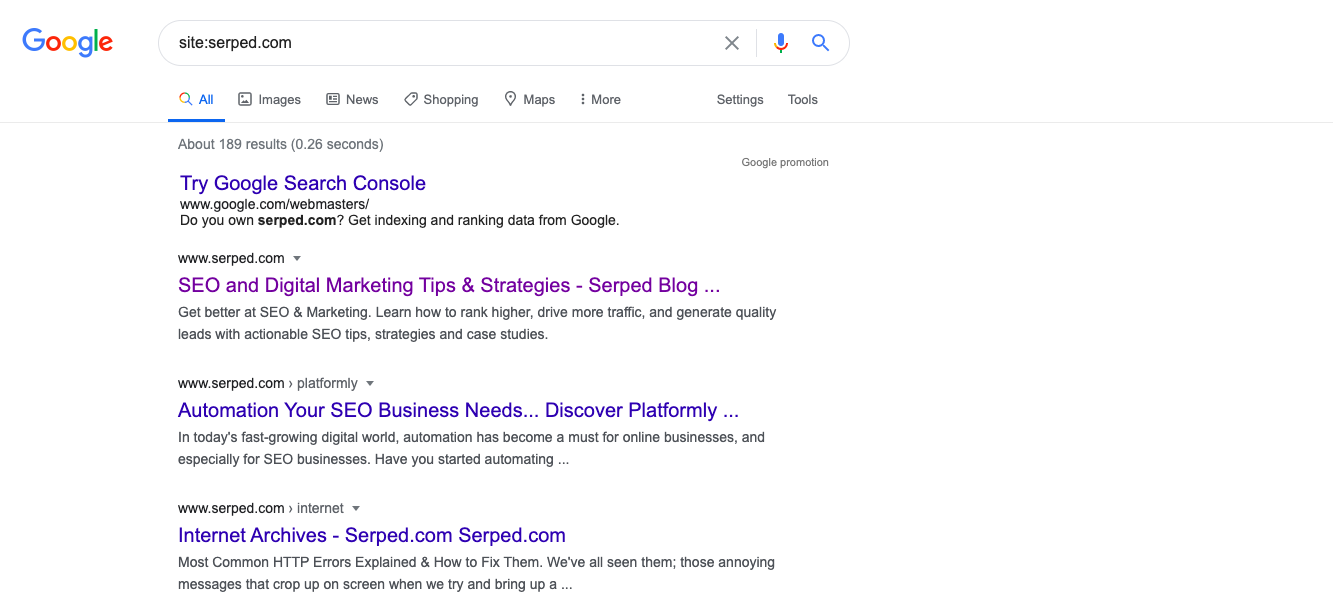
This search will allow you to find out how many pages on your website are indexed right now. This will help you figure out if there are any pages on your website that haven’t been correctly crawled. Once you have this information, you can track crawling errors.
Of course, this is not an exact listing of how many pages on your website have been crawled. If some pages do not show, there can be a few other reasons why this is the case:
- If your website is brand new, it might not have been crawled yet. In this case, we recommend installing Google Search Console to accelerate that process.
- There might be no external websites linking to your website. We advise you to start with a link building strategy from the beginning to avoid this.
- Navigation on your website might make it difficult for bots to crawl it.
- Your site has been penalized by Google for some reason, blocking it from showing on search results.
We won’t go into details about penalizations from Google in this article, because they don’t happen often. Unless your website uses spammy tactics, you don’t need to worry about being penalized. ⛔
However, there might be pages you don’t want Google to crawl: such as pages with duplicate content, test pages, landing pages for your campaigns, and so on. To keep Google from crawling those pages – and making sure it indexes the other ones – you should use a robots.txt file.
Robots.txt
This file should be located at the root of your domain (such as yourdomain.com/robots.txt), as it helps Google understand how to crawl your website. If the file does not exist, Google will crawl all pages. If you have a robots.txt file, Google will follow the rules set out on it while crawling your website, thus indexing only the URLs that aren’t blocked by the file.
However, if your robots.txt file has errors, Google will not be able to crawl your website correctly, thereby preventing it from being indexed.
Using Google Search Console to Define URL Parameters
Sometimes, you may have a need to use dynamic URLs. There are two types of URLs: static and dynamic. A static URL is something like this: https://www.serped.com/domain-authority. This URL is always going to look the same, no matter where you access it from.
Dynamic URLs depend on the search terms used, and are commonly used on eCommerce websites. Let’s say you’re making a search on Amazon. As you click through, your URL changes and adds parameters to match your search filters. So you get a URL like this: https://www.amazon.com/s?bbn=16225006011&rh=n%3A%2116225006011%2Cn%3A11057241&dc&fst=as%3Aoff&pf_rd_i=16225006011&pf_rd_m=ATVPDKIKX0DER&pf_rd_p=fd971cf1-cdbc-4301-8c91-0a56b1c1e13f&pf_rd_r=MFAGVPVN324FNGJQ2QDC&pf_rd_s=merchandised-search-4&pf_rd_t=101&qid=1488484834&rnid=16225006011&ref=s9_acss_bw_cts_AEVNBEAU_T3_w See the difference?
However, you can use Google Search Console to define which pages should be crawled and indexed according to these parameters. You just need to set options such as “crawl no URLs with the X parameter” in order to avoid crawling of duplicate content.
2.2. Common navigation issues ⛵
There are several aspects in website navigation that can affect how your website is crawled, and whether it is crawled correctly or not. Below are a few common navigation mistakes that can prevent your website from being crawled properly:
- Different navigation in the mobile version and the desktop version.
- Google has improved the way it crawls Javascript items in the navigation, but it is still recommended to use HTML for it. Using Javascript for the menu buttons is not recommended.
- If users see different content according to a defined personalization, it can keep Googlebot (Google’s crawler) from accessing all the pages. It can even lead to a penalization if Google considers this as cloaking on your website (a black hat technique).
- Make sure all your primary pages get links to them from the homepage – Googlebot uses links to travel between your pages.
Using sitemaps
Sitemaps make sure all your relevant pages are crawled and indexed. This is a major step in order to create a clean information architecture. Information architecture refers to the way pages are connected and labeled in order for visitors to navigate easily through your website.
A sitemap, as the name suggests, is a map of your website, including all the URLs you want bots to crawl. Our first advice is to follow Google’s rules for sitemaps. Other than that, you should make sure that your sitemap does not include URLs you are hiding in your robots.txt and vice versa. After that, you need to upload your sitemap to your website, in the root of your website (just like your robots.txt), and submit it on Google Search Console (GSC).
We mentioned Google Search Console above, and we definitely recommend using it even if you don’t have to define URL parameters. GSC is a powerful tool for your SEO, and it can help you detect crawling and indexing errors quickly.
If your website is not updated often, GSC can help as well. If your website does not update frequently, Google bot will stop crawling it for updates. Using Google Search Console, you can force a crawl when you’ve added some blog posts or made some major changes in your website structure and content.
2.3. Common crawling errors
While crawling your website, crawlers can find errors – just as we mentioned previously. You can check those on Google Search Console: however, you need to know what caused them and what kind of errors they are in order to fix them. We’re going to list the main types of crawling errors you’ll usually encounter on your website.
4xx Codes
This type of code is due to a client error. What usually causes these errors is usually either a URL typo, broken redirects, or the page has been deleted. The most common is error 404. Since this happens on every website, we recommend having a page designed to show your users when there is a “404 – not found” error, such as the one below:
5xx Codes
5xx codes are due to a server error. Google Search Console has a tab dedicated to these errors only. When you have a 5xx error, it means the server was unable to fulfill the request (performed by a user or by a search engine). Often, what happens is the request for this specific URL timed out. When a request times out, bots will abandon it.
To solve these issues, you need to fix your server connectivity.
How To Use 301 Redirects ↪️
Luckily, there is a way to prevent these errors: using a 301 redirect. 301 redirects are permanent, so they’re perfect to make sure users get to the right page on your website.
Redirecting ensures that all the “link juice” (defined by page rank and page authority) flows from the old page to the new one. It also helps Google index your new page correctly and quickly. When it comes to UX (user experience), it also improves the way users interact with your page, since they will be able to find it and see its content.
Avoid Too Many Redirects
If you need to redirect users to a page temporarily, you can use a 302 redirect. However, that shouldn’t be the case for too long, as it will not share the link authority from the old page, and it might affect your ranking.
You should make sure that the new page you’re directing users to has relevant content according to the old page. If this new page does not match the original content, bots are going to find that it is not relevant for the search that was made by users, and your rank will drop.
When it comes to ranking, it’s important as well to avoid too many redirects. If you redirect your users too many times, it can both affect your ranking and user experience too. Make sure to use 301 and 302 redirects only when strictly necessary.
3. Indexing
3.1. How do search engines index your website?
Now, making sure your pages are crawled does not mean you’ve ensured that they are going to be indexed. Bots render your page with all the content and all the code, analyze it, and save it to be shown on search engine result pages (SERPs, in short).
3.2 How do you see how your website is being indexed by Google?
To find out how your page has been indexed, you can check the indexed version of it by clicking on the arrow next to the URL on search results:
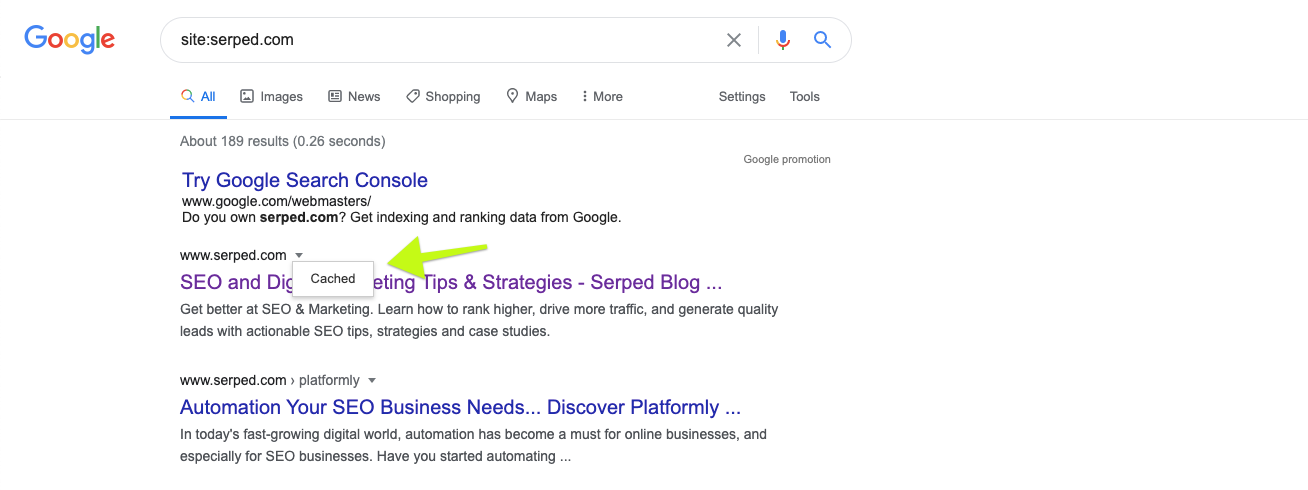
The arrow will show you a “Cached” button you need to click. There, you’ll find out how your page is seen by search engines:
3.3. Can I get removed from the index?
There are instances where a page is removed from the index, therefore not showing on search results. This can be intentional or accidental. These are the most common reasons for a page to not be indexed:
- 4xx and 5xx errors can cause that page to be removed from the index.
- The page was deleted and a 301 redirect wasn’t implemented.
- The page was hidden intentionally by deleting it and setting up a 404 page.
- A noindex tag was added to the page to prevent it from being indexed.
- Google penalized the page manually because it didn’t comply with its Webmaster Guidelines, causing the page to be removed from the index.
- A password was added to restrict access to the page, keeping it from being indexed.
As you can see, there are a few reasons why your pages might not be indexed. It’s not always an issue per se: sometimes you might want some pages of your website to remain private, for many possible reasons.
However, if the de-indexing wasn’t intentional, there are a few things you can do to fix that. You just need to install Google Search Console. In GSC, you can find the URL Inspection tool, which will show the status of a page. It allows you to see what is causing a wrongful de-indexing.
Also in GSC, you can find the “Fetch As Google” tool. In this tool, there is a button called “Request Indexing”, which is the one you should use when submitting a new page for the search engines to crawl.
“Fetch As Google” also allows you to see if the cached version of your page is up to date.
3.4. Telling search engines how to index your website
Search engines follow specific protocols when it comes to deciding whether to index your pages. In the following section, we’ll show you the common ways to hide or show specific URLs according to the pages you want to index or not index.
Robots meta directives
Meta directives are instructions that you give to bots in order to index only the pages you want. These instructions include the option to not pass any page authority to links on a specific page, or not to index another specific page.
Meta tags are included in the <head> of your HTML pages using the Robots Meta Tags container. They can also be added to your HTTP header using the X-Robots-Tag.
Robots Meta Tag
In the <head> of your HTML, you can use a Robots Meta Tag. It can be used to exclude all search engines or a specific one. These are common meta directives:
- “noindex” tells search engines to ignore a specific URL, preventing it from being crawled and indexed. There’s also the “index” directive, but it is not commonly used since bots index all pages unless there is a directive requesting otherwise. You can use noindex on private pages, especially ones that have content from users you want to keep hidden.
- “follow” and “no follow” allows you to define if link equity is going to be passed on from that URL. By default, all pages have “follow” activated. “Nofollow” will prevent the link equity from being passed on to the links on that page. Usually, you’ll find social media links using “nofollow”. It should be used together with “noindex” to make sure the pages you want to keep private are not crawled nor indexed.
- “noarchive” prevents Googlebot from saving a cached version of each page. It is commonly used in eCommerce websites, because prices change often and you don’t want visitors to see the old price tags. By default, all pages are archived in search results, showing a cached version of the page. Noarchive prevents that.
You can use all of these tags at the same time, as long as you respect the syntax for the robots meta tag.
X-Robots-Tag
This tag will be placed in the HTTP header, and it allows for more flexibility than meta tags. You can set up a tag that will block entire folders in your website, or hide specific files or file types from being indexed.
We recommend using a X-Robots-Tag when you have to block a large volume of content, since it is more efficient than using the robots meta tag. The robots meta tag is ideal to block specific URLs, but if you have a lot of content to prevent indexing for, the X-Robots-Tag is the way to go.
3.5. What is mobile-first indexing and how does it affect my website?
Mobile-first indexing was first announced in 2018, and it is now working in full functionality. But what does mobile-first indexing mean?
Well, as the name suggests, Google now starts indexing your website from the mobile version and uses this version as the starting point. This also means that your mobile version has a great effect on your ranking.
So, it has become imperative to have a responsive website design, making sure that visitors coming from every device have a great experience with your page.
Mobile-first indexing also affects crawling: if you have a mobile version, it will be crawled first. However, if you only have a desktop version of your website, it will be crawled anyway; but your ranking might suffer if you’re competing with websites that have a mobile version.
It should be noted as well that if you use responsive design, your ranking should not be affected by mobile-first indexing.

4. Ranking
Now, we arrive at the part that SEO professionals care about the most: ranking. Crawling and indexing are requisites for ranking, but if your website is properly crawled and indexed and your ranking is still not high enough, you need to dig further.
In this section, we’ll explain how ranking works and what search engines want from your website in order for it to rank high.
4.1. How do search engines rank URLs?
Ranking ensures that when users type a search query, they will get relevant content in return. This function organizes results (SERPs) in order to show content from most relevant to least relevant.
Algorithms define how all websites are ranked. Google updates its algorithm quite often, with the goal of improving the quality of search results. To find out if you’re following the quality guidelines, please check this help article from Google. This link is quite helpful if your ranking has suffered recently due to an algorithm update.
The goal of search engines has always been to deliver the best results for a search query. However, if you work with SEO, you have probably noticed that a lot has changed from when search engines first appeared and how you do SEO these days.
Take keyword stuffing, as an example. In the beginning, if you wanted to rank for a keyword, you’d repeat that keyword as much as possible in your content. However, that resulted in a terrible user experience, since users don’t behave in the same way that search engines used to in the past. Users want quality results that answer their question or request, not text that’s made up for bots.
Fortunately, as time goes by, bots have become quite apt to understanding which results provide users with a better experience. Keyword stuffing now results in penalizations from Google and other search engines.
4.2. How do you rank higher?
There are three main factors that help you rank higher without being penalized: content, links to your website, and RankBrain. We’ll describe how each works in this section.
Links in SEO
There are typically two types of links when it comes to SEO. Backlinks (also known as inbound links) are links from one website to another. On the other hand, internal links are those that connect pages on the same website.
Links to your website can have a positive impact on your ranking if they are from websites that are considered authorities in your subject. However, if you get links from spammy or low-quality websites, your ranking might suffer. If you get links from the wrong kind of website, you might even get flagged for spam.
If you have no links pointing to your website, your authority on the subject is unclear, so this factor will not increase nor decrease your ranking.
PageRank is part of Google’s algorithm, and it’s PageRank that defines whether you get a better ranking according to the quality and quantity of backlinks to your website. This ranking factor works under the assumption that the better the links you have, and the more links you have from authoritative websites, the more relevant your website is for users.
Unfortunately, it’s become very common to find websites that buy backlinks; we do not recommend that at all. PageRank is able to understand which backlinks are natural and organic (resulting from other websites considering your content useful) and which links are unnatural, meaning they were bought or are the result of a link exchange. Link exchanges should be avoided too unless the website is highly relevant for your content and has a good DA (domain authority).
Content in SEO
Content is the main pillar of on-page SEO. It includes everything that is on your website: text content, videos, images… In order for your website to rank higher, your content must answer the question implied in the search.
For each search query, there are thousands of websites competing for number one on the SERPs (search engine result pages). How do search engines know which website provides a more comprehensive answer?
Well, an important factor is search intent. If a user is looking for information, your website should provide it. If the user’s intent is to buy, we’re looking at another kind of content.
In order to rank for a specific keyword, you need to find what other websites that rank already provide for users. How long is the content? The more comprehensive your answer to the search query is, the easier it will be to rank high for it. Your focus should always be on what the user wants to accomplish with their search: if your content is good for users, it will be great for bots.
4.3. What is RankBrain?
RankBrain is part of Google’s algorithm. But why is it so important for your ranking? Well, RankBrain is the part of the algorithm that uses machine learning to constantly improve search results and make them more relevant for users.
Machine learning implies a constant iteration of the algorithm functions, by using data collected in order to improve its performance. So, RankBrain is constantly learning new ways to rank websites in SERPs.
As an example, let’s say a result that is on the 7th position of search results gets more clicks than the number one result, and a lower bounce rate from users. RankBrain will “learn” that this result on 7th position is more relevant than the others above it and bring it up to the top of the search results.
![]()
4.4. Are search results changing?
In the beginning, search engines were simple mechanisms. There was a page with “10 blue links” that was shown to users for each query, and that was it. Your goal was to place as high as possible on this list.
However, over the years, Google has implemented changes to this “10 blue links” format, and now each search returns other formats as well, such as:
- Paid advertising (Google Ads)
- Sitelinks
- Featured snippets
- Local Map Pack
- Knowledge panel
- “People also ask”
Google is adding new features to its search results constantly. This caused a bit of panic among SEOs in the beginning, since organic results were pushed down on the list, and users were clicking ads and “zero-result SERPs” started appearing: result pages that only showed an answer to the user’s question and a button to “view more results”.
The goal of these experiments was to improve the way search engines answer the question implied in the search query. If users can get an answer to their request without having to click through, the experience is better for them, because it’s faster than having to go through a website looking for an answer.
So, if you have an informational query, you’ll probably find the answer in a featured snippet. If there is only one answer to the query, you can get a knowledge graph or an instant answer. Local queries are answered using the Map Pack, and transactional questions get results from Google Shopping.
User experience is everything. If it can be improved using other formats than links to websites, that’s what is going to happen; and the only way for SEOs to handle this is to adapt.
4.5. Local Search
Google has its own directory of services from which search results are extracted to show up for local queries. If you or your SEO client has a local business or provides services in a specific area, you need to create an entry on Google My Business (GMB).
Among results from GMB, Google uses a specific ranking to show each result. This ranking is based on relevance, distance, and prominence.
Relevance has to do with how well the business fits the search query. To make sure the business shows for the right keywords, you have to optimize your Google My Business entry and make sure you describe exactly what your business offers.
If you’re searching for a local business, you are interested in companies that are close to you. Even though distance is not often taken into consideration when it comes to other types of searches, in local search it is a major factor for ranking.
Google tries to show users the businesses that are more prominent in the offline world too. In order to produce the more prominent results, it relies on reviews from users (collected from Google). The more positive reviews a place gets, the more likely it is to show up for local searches.
Business listings on other sources can also be taken into account, usually from websites such as Yelp and other similar directories. Google pulls data such as name, address and phone number (NAP details) from many sources, adding that information to its database. Links and articles can also be used to collect data for Google My Business.
You should optimize your listing as you would for organic search. When defining local ranking, GMB also takes into consideration the ranking of the company’s website in order to show more relevant results to users.
Wrapping Up
Knowing how search engines work is important in order to make sure your SEO work is on point. Even if you don’t do SEO, as a client, it is important to know what your SEO professional needs to take care of and to align your expectations with reality.
SEO work is not easy, and it is constantly changing. From mobile-first indexing to zero-result searches, there is a lot of information to take in at all times. Every year, Google launches a new core update so it’s essential for SEO professionals to keep on learning all the time.
If you use SERPed.net, it can help with you different aspects of your SEO campaigns, including keyword research, rank tracking, and much more, improving your ranking within Google. Not using SERPed yet? You can check out our plans here. You'll see it will make a huge difference in your SEO strategy.
Our comment box is always available for you if you have any questions. You can also find us on Facebook, Twitter and LinkedIn.

